
A Data Mesh Journey
Iterating on a data mesh while modernizing your stack

Many data teams today aspire to implement a data mesh believing that decentralizing data ownership will result in a more agile organization that can derive value from its data faster. I won’t bother writing any kind of “how-to” guide on transitioning into a data mesh, but would rather like to share some first-hand learnings!
Teams today are looking to transition from a centralized data ownership concept towards a fully distributed data mesh, believing that decentralization will drive scale and accountability across the organization. This may be true, but that change management curve is long and arduous. There are many pieces of data ownership that can be centralized or decentralized.
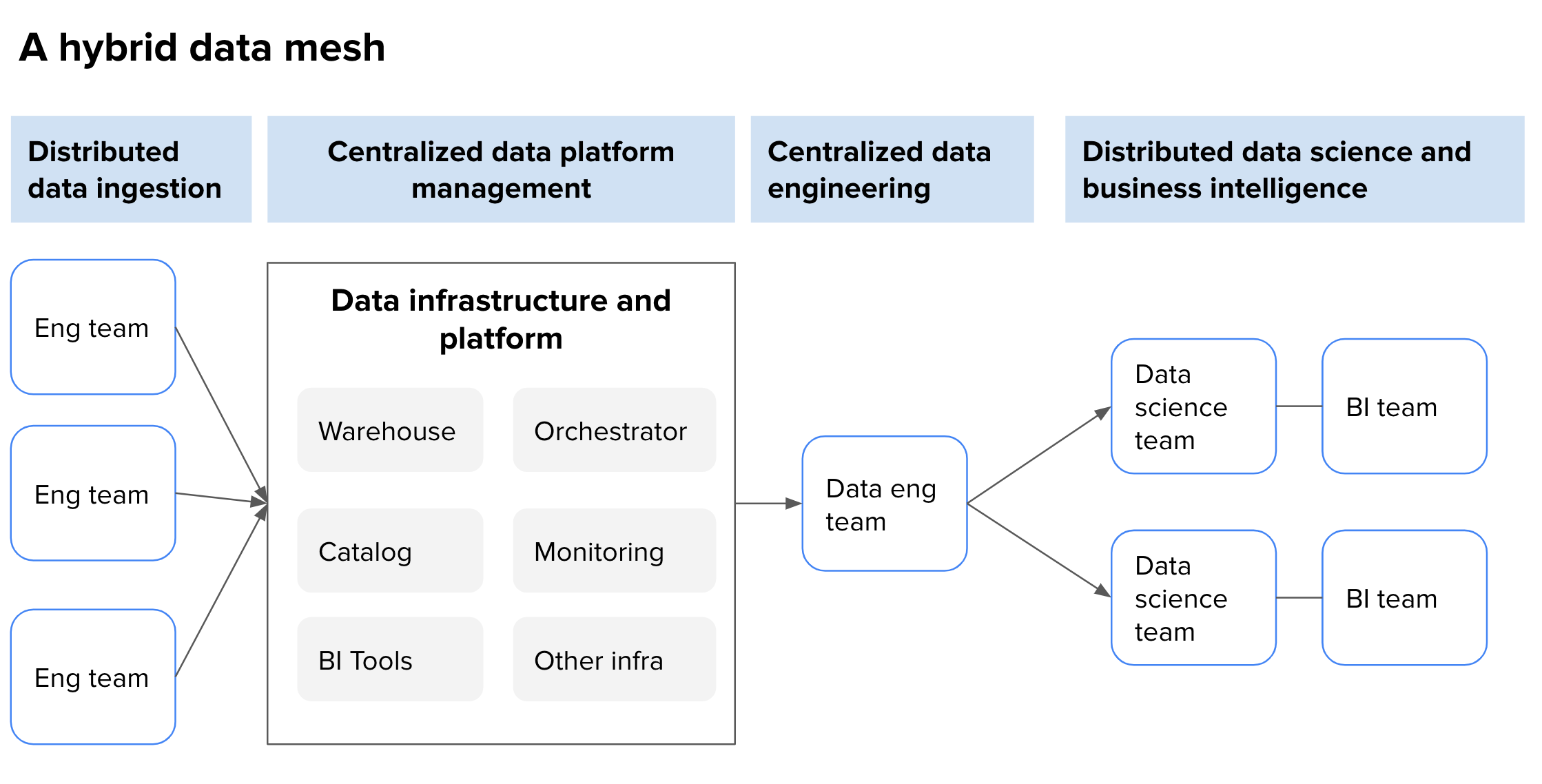
Below is an example of a hybrid data mesh. This is meant to serve as a more realistic example of how to transition from centralized to more decentralized.
Data infrastructure and platform are centralized
Data engineering is centralized
Data ingestion to Snowflake is distributed to product/engineering teams
Data science and business intelligence are distributed across Finance, Risk, and product/engineering teams

Why a data mesh - start with the problem statement
When beginning a data mesh journey, it’s critical to define the problems to be solved. Some likely problems include the data stack being too old and requiring modernization, or the fact that most analytics get built in ungoverned sandboxes. However, the most common problem to focus on relates to scale. Teams have limited data engineering teams that may have to serve all data use cases (ingestion, transformation, serving, etc). In most cases, this model for supporting data doesn’t scale and often creates so much tech debt that the entire organization is paralyzed.
The only way to continue with a centralized data team is to 10x its size. But as a cost center, data teams would never get that kind of investment. In order to support a scaling company with several product lines, the most economical option is to federate ownership of data out to the engineering teams that generated the data. They key is to show leaders that you can provide more reliable data for analytics use cases and build a foundation for a data-driven culture without a 10x increase in the size of your data department.
Make sure you’re solving a real business problem with the data mesh. A classic example is to scale data support for a company with several product lines.
How to generate momentum
Once the problem statement is set, there’s a need for a catalyst to generate momentum. What team is going to gladly accept new data management responsibilities without any immediate benefit to them and no increase in headcount??
At this point, it helps to understand the broader goals of the company and what will affect most of your stakeholders. For example, if you’re hitting scale limitations on a legacy data warehouse, migrating to a new structure also helps address issues with the legacy stack. It helps to identify what will help enable success for your stakeholders across the business and not just in data. By doing so, the success of the data mesh is no longer a data-team goal but a company-wide need.
Align your data goals with the company goals to gain supporters and momentum.
Pivoting based on stakeholders and feedback
Great! We have a need and some momentum. In order for a data mesh to work, however, many teams across the company need to accept and excel at their new data responsibilities. And these responsibilities can be wide and complex.
While teams may be willing to participate in the vision of a data mesh, teams of software engineers used to building consumer facing applications often know little to nothing about data. Many of them have little experience with SQL and have never heard of ETL/ELT. Making the data mesh work requires teams to take on a whole new competency that they may not know how to train, hire, or develop.
In many cases, a full data mesh where teams owned all their data (ingestion, transformations, etc) is simply not realistic in a single go given the current expertise and experience . Change takes time. Developing data experience and culture doesn’t happen overnight. Being able to pivot at this stage is what brings you to an intermediate step, or a hybrid data mesh.
For example, you can start with ingestion. Engineering teams are the ones who generate their data and it’s a lot easier to convince engineering leaders to own ingestion of their own data than to convince them that they also had to apply transformations and business logic to that data for downstream analytics users. Instead of trying to shift to a full data mesh overnight, it helps to meet your partners where they were at.
Understand who your data mesh partners are and what expertise they have. Meet them where they’re at so you can help them fall into a pit of success as they pick up data mesh responsibilities.
Takeaways on the iteration cycle
As a recap, here’s a few takeaways.
Make sure you know what problem the data mesh solves.
Have a catalyst to generate momentum and support from others beyond the data team.
Meet your partners where they’re at and help them fall into a pit of success. This ensures that teams taking on data mesh responsibilities can start off with a win
Make your goals the company goals. Pushing for the data mesh needs to translate into something that teams outside of data care about and will rally behind.
Keep iterating on the mesh! Organizations and models are living things and there isn’t a single destination. A hybrid model may help you make progress towards your long-term vision.
In my next post, I’ll break down several dynamics to consider if you’re wondering if a data mesh is the right next move for your organization with examples from our journey. Stay tuned for more!