
Harness engineering when reasoning is exponential
6 principles for building a harness that grows with your models

Your team went all-in on AI a few months ago, and everyone’s been maxing out their Claude subscriptions since.
Watch two of your sales reps on the same Monday.
The first rep set Claude Cowork up to read his inbox, research the account, and draft a prep doc before each call. This morning it didn’t run, because his laptop was closed. Yesterday it ran, drifted halfway through, skipped the research, and filled the gaps with things that aren’t true. He spends the twenty minutes before his call fixing it.
The second rep’s agent runs on a schedule at 7am no matter where his laptop is. The workflow around it enforces each step, does the research, checks the data, and has learned over weeks which accounts and signals he actually cares about. He reads the brief while sipping coffee instead of troubleshooting, and enters the day fully prepared.
Same model, same task. One rep is editing skill files and remembering to press go; the other has a system that quietly makes him better at his job every day.
This is harness engineering: the scaffolding around a model that turns raw reasoning into work that reliably gets done, meeting people where they do work.
Harnesses aren’t new; we’ve been wrapping scaffolding around language models since the GPT-3 days. But they’ve completely changed in just a few years, especially since reasoning jumps from Opus 4.6 and forward. Andrej Karpathy has argued for treating scaffolding as disposable, built to be stripped away as models improve.
So how should we approach harness engineering when we build it not for Opus 4.8, but for whatever lands two generations out, call it Fable 6.0 or GPT-7, when reasoning has 10x’d again?
The trick for harness engineering is building with principles that amplify the human and AI loop while giving you flexibility and accountability as reasoning improves.
The agent harness, a brief history
Let’s start from the top. Agent = model + harness.
The model reasons; the harness is everything around it that decides what it sees, what it can touch, what it remembers between sessions, and how its work gets checked before it ships.
Chiefly, a harness manages all the scaffolding around what your AI model does. Tomasz Tunguz has a great breakdown of a harness’ components, such as context, tools, orchestration, and more.
In the early ChatGPT era the harness was there to hard-code a workflow: LangChain wired prompt into prompt into prompt with LLMChain, SequentialChain, and AgentExecutor. CrewAI gave each agent a role, a goal, and a backstory and ran the crew on a script.
These were reasonable bets for models that couldn’t be trusted to plan, but also required lots of engineering and wiring just to get an agent to do reasonable work.
Then the models got smarter.
MCP and CLI enabled another way to call tools, structured outputs went native, context windows went to 1M tokens, and the chain after chain approach collapsed into a single model call.
LangChain conceded developers had hit a “controllability wall,” decided the right abstraction “was little to no abstraction at all,” and in October 2025 moved its own chain era into a package named langchain-classic. CrewAI bolted on a deterministic Flows layer and pivoted toward governance.
What replaced chains wasn’t a better chain. It was a different category of thing: agent loops, state machines, workflow graphs, durable execution, evaluator loops, and a new term - harness engineering.
What harness engineering looks like today
Now, it’s summer 2026. We got a taste of Fable 5 but most folks are using Opus 4.8 or GPT 5.5. Teams no longer build a harness from scratch.
Anthropic packages the Claude Code loop as the Claude Agent SDK and, since April, runs the whole thing for you as Managed Agents. OpenAI’s Agents SDK enables a model-native harness with sandboxes and memory, and Symphony turns an issue tracker into the control plane for a fleet of Codex agents.
Open source agents like OpenClaw and Hermes have proliferated, primarily as personal assistants or small scale business orchestrators.
Just last week, I saw someone demo their OpenClaw harness that scans all their GitHub PRs, open tickets, and summarizes their team’s progress for daily standup. This saves them the painful daily ritual of “is this ticket done or in review? And where exactly is the PR?”
It blew my mind.
And just a few days ago, Databricks open-sourced Omnigent, an early “meta-harness” that sits above Claude Code, Codex, and the agents you write yourself and treats each as interchangeable.
Imagine something like Google Docs, a collaborative multi-player environment, where you can bring whatever model you want, and coordinate and share your agent work across the team.
This is the future of agentic work.
What does a 10x smarter model look like?
If we extrapolate the curve we’re already on, we see a few things with the next generations of foundation models, when Fable 6 or GPT 7 come out.
Persistent long-horizon memory.
Effectively unlimited context through a combination of massive context windows, retrieval, memory compression, and learned state management. Models can reason across years of company history, code changes, decisions, and conversations.Stronger world models and causal reasoning.
Models get better at identifying implicit constraints, second-order effects, organizational dependencies, and hidden assumptions. Less pattern matching, more coherent internal modeling of systems.Long-duration autonomous execution.
Models can maintain objectives across multi-hour or multi-day tasks, dynamically replan, recover from failures, and manage large execution graphs without losing intent.Hierarchical planning and decomposition.
Models are more capable at breaking large goals into sub-goals, assigning work to specialized agents, tracking dependencies, and synthesizing results back into a coherent outcome.Native multimodal reasoning.
Text, code, documents, spreadsheets, diagrams, screenshots, meetings, audio, and video all become first-class reasoning inputs rather than separate model capabilities.
How to harness when reasoning 10x’s
If that is the model of tomorrow, does our harness of today become obsolete, along with all our work and efforts to set up that platform?
Not necessarily.
If we build with core principles that anticipate the future, we can deliver what we need today and tomorrow:
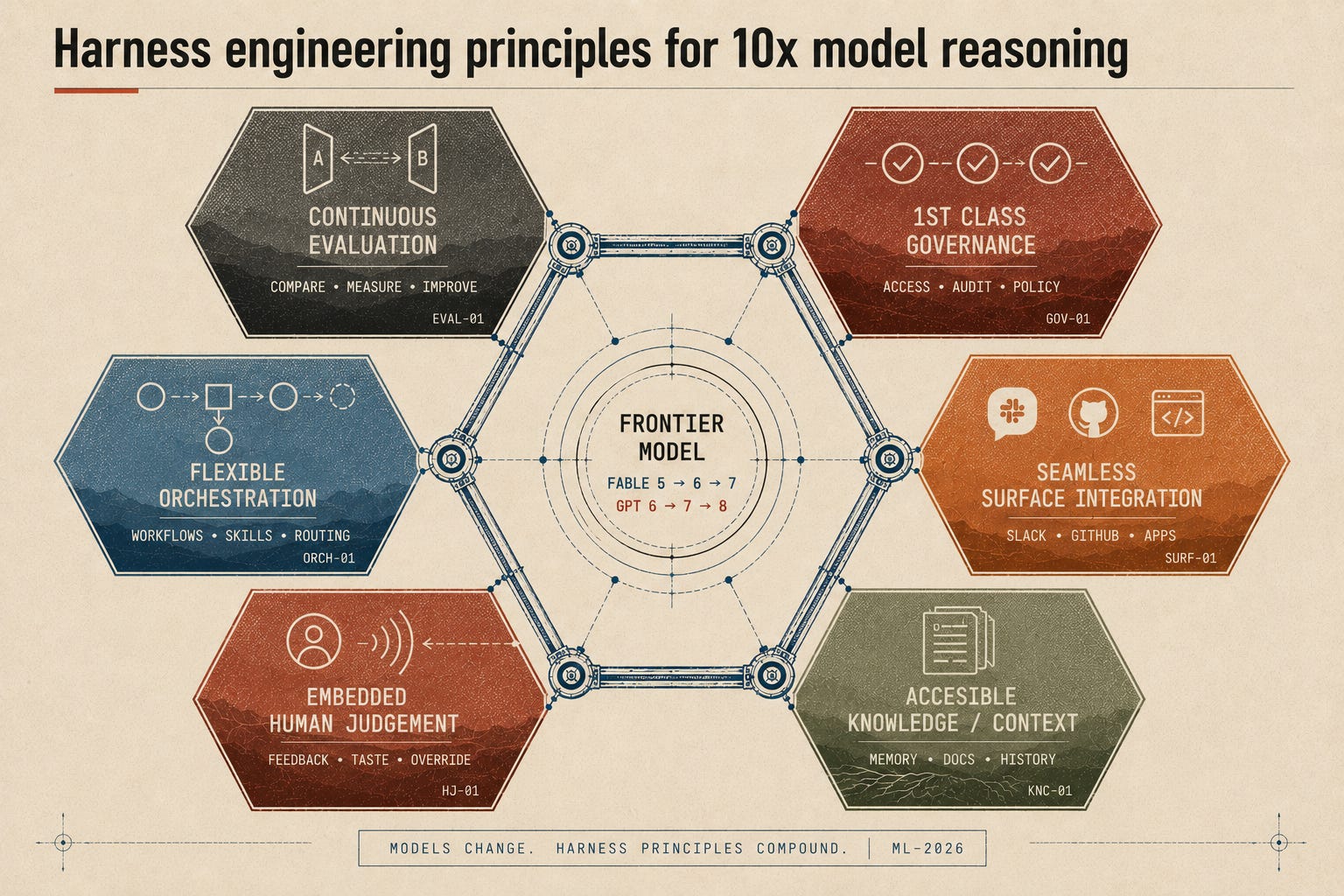
1. Context and knowledge as the backbone.
The harness connects and amplifies your expertise and your company’s knowledge: docs, decisions, code history, eval traces, and more. A smarter model still wakes up knowing nothing about your business. It just mines a good context store faster, which makes that store more valuable, not less.
2. Human judgment, captured.
A harness shouldn’t only do the work. It should catch the taste, the approvals, and the corrections your people supply and feed them back into the system.
As Satya Nadella argues, “the real opportunity is not in picking the best model but instead in building a learning loop on top of models where human capital and token capital compound.”
3. Flexible orchestration that evolves.
Keep determinism where the business demands it, the checkpoints, retries, approvals, and SLAs. But design your harness in a way where those checkpoints can change over time. The agent topologies you have today will be obsolete in 6 months, so flexibility is key.
4. Continuous evaluation and verification.
As agents get more autonomous, you need continuous measurement: task success, regressions, golden sets, cost, and hallucination checks. Have a different model family grade the work, because models flatter their own output.
5. Governance and security are 1st class citizens.
A more capable agent taking on work autonomously makes identity, audit, permissions, and policy non-negotiable. As the work gets more important, so does the audit trail. That is exactly what Omnigent’s policy layer reaches for, and it is what lets you give an agent more rope without losing the ability to watch and stop it.
6. Surface integrations, meet your users where they’re at.
The harness that wins isn’t backend plumbing. It lives where the work happens: Slack, Linear, GitHub, email, the CRM, the IDE. It meets people where they already are, the way a brief that lands in Slack at 7am beats a tool someone has to remember to open.
A harness worth building
It’s paralyzing to consider how to invest in your harness and agent platform right now, do you try building something that might get obsolete in 6 months? Or do you risk not reaping the gains from a harness that amplifies your team’s abilities?
The answer is to do both, build a harness for today that grows with the models of tomorrow. Understand and anticipate how reasoning jumps will change the ways agents and context get managed, then build your harness with the flexibility that accounts for this change while instrumenting the governance necessary for agents to take on more work.
Harness engineering isn’t going anywhere; it’s still early. Build the harness that amplifies the loop between your people and the model, meet your team where they already work, and design today for the model that lands next year.
That is how you build something that gets more valuable every time the model does.
Thank you for this article - it teaches and crystallizes something for me: as model capabilities improve, the strategic value shifts from the model itself to the harness around it.
Then, enterprises eventually face a second-order problem: not how to build a harness, but how to govern thousands of them.
Once agents are embedded across workflows, teams, partners, and vendors, harness engineering becomes a control-plane problem: identity, policy, observability, auditability, and the ability to manage authority at scale.
The more capable the reasoning becomes, the more valuable the governance layer becomes.
This is highly complementary to a multi-player agentic AI article I’m working on.